DataIntegrityViolationException에 대해서
짧은 근황을 먼저 얘기하자면...
올해 3월부터 이직을 하게되어 삼쩜삼(자비스앤빌런즈) 백엔드 엔지니어로 현재 이직하여 회사를 다니고 있다.
나중에 다른 포스팅으로 해당 부분은 잘 작성해보도록 하겠다.
이전 포스팅인 @Transactional 제대로 알고쓰기 에서는 무지성 중첩 트랜잭션에 대한 포스팅이었는데,
이번에는 좀 다른 케이스였다.
해당 예외가 발생하는 것이었다.
회사에서는 Mysql을 RDBMS로 채택하여 사용해서 아래와 같은 예외가 보였지만, 예제에서는 H2 DB를 사용하기 때문에 같은 에러메시지는 아니지만,
내용은 똑같다는 점을 일단 알고 넘어가면 좋을 것 같다.
HHH000099: an assertion failure occurred (this may indicate a bug in Hibernate, but is more likely due to unsafe use of the session): org.hibernate.AssertionFailure: null id in com.lsj8367.github.DemoEntity entry (don't flush the Session after an exception occurs)이러한 예외가 나서 에러 로그에 StackTrace를 같이 찍어주고 있었기 때문에 지켜보게 되었다.
해당 예제를 구현한 것은 깃허브에 있다.
코틀린으로 코드가 구성되어있지만, 알아보기는 정말 쉬운정도의 코드라서 문제없이 읽을 수 있을 것이다.
구성하기 좋게 Facade -> Service -> Repository 로 단방향으로 흐르는 구조로 구성하였다.
실제 코드와는 완전히 다르고 정말 예제만을 위해 이렇게 구성하였다.

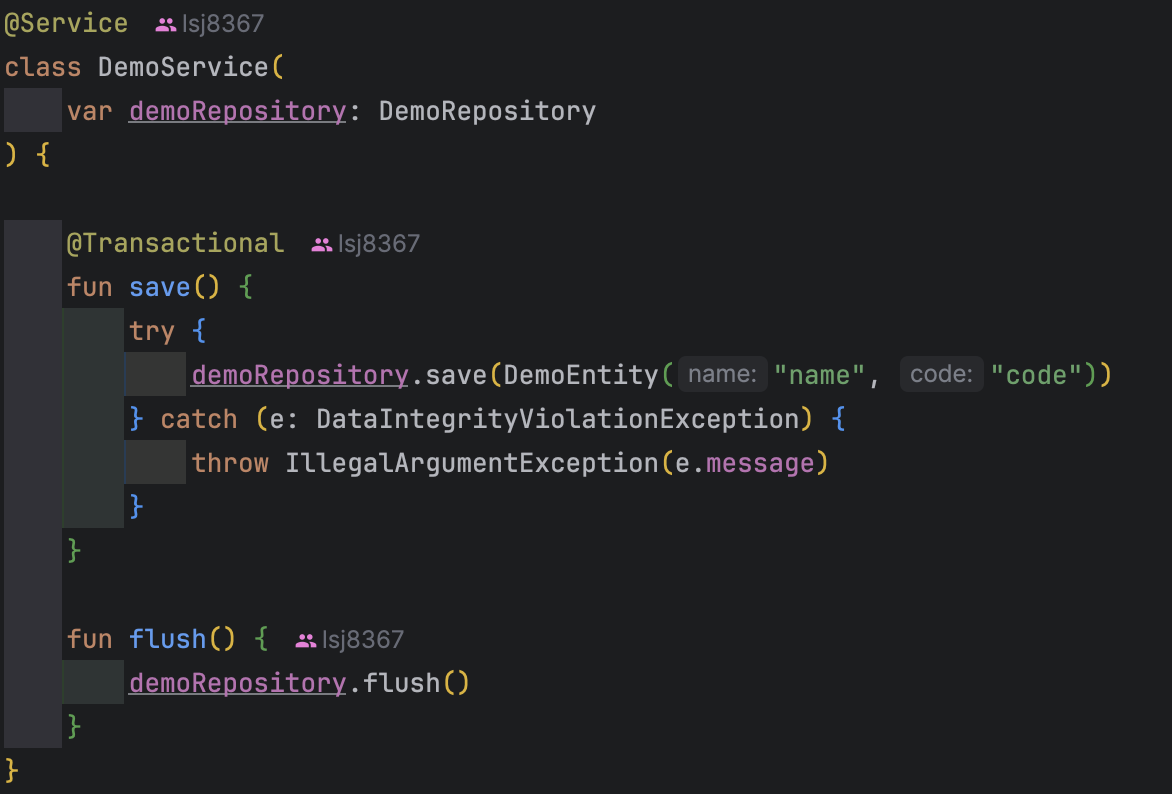
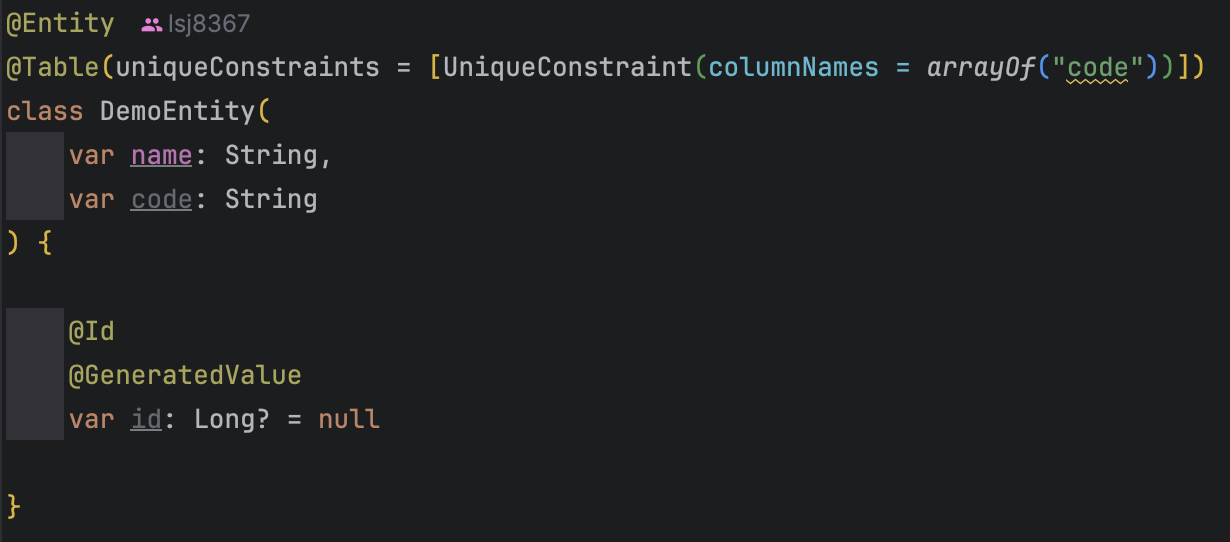
이제 Service Layer의 save 로직은 name 값엔 "name"을 code값엔 "code" 를 무조건적으로 저장하도록 구성했고, entity 조건엔 unique 제약조건으로 code 값을 설정해주었다.
그래서 첫 1회는 저장이 정상 수행되며, 2회 수행시에는 uk 조건을 만족하지 못해 예외가 발생할 것이다.
정말 잘 발생하는것을 볼 수 있다. ㅋㅋㅋㅋ

근데 이제 여기서 문제인것은,
중복 예외인 DataIntegrityViolationException 을 catch 절에서 잡고있는데 어떻게 된 것일까?
이 부분을 생각해봐야 한다.
해당 부분을 알기 위해서는 JPA를 사용할 당시에 1차캐시를 기억해야 한다.
1차 캐시는 말 그대로 영속성 컨텍스트에 해당 엔티티 값들을 저장하는 방식인데, 우리는 당연스레 쿼리를 나가는 것을 생각하지 않으니 저장 객체를 핸들링 하는 것처럼 코드를 작성하게 되는데 이부분에서 문제가 발생했던 것이다.
일단 당연한 얘기지만 @Transactional 내부에 있기 때문에 로직들은 전부 트랜잭션이 끝나는 부분에 맞춰서 쿼리가 나갈 것이다.
그렇기 때문에 우리는 DataIntegrityViolationException을 catch로 잡아줘서 커스텀하게 던져주는 IllegalArgumentException은 잡히지 않는 것을 볼 수 있다.


이런식으로 IllegalArgumentException을 던지는 것으로 체크가 되지 않는 것을 볼 수 있다.
그러면 왜 때문에 DataIntegrityViolationException이 중간에 발생했을까?
해당 사항은 위의 코드에선 flush() 를 명시적으로 호출해주는 경우에 발생했다. (실제 쿼리가 이때 반영되기 때문이다.)
그러면서 ExceptionHandler를 통해 500예외를 핸들링하는 방식으로 구현되었다.
실제 업무 로직에서는 findAll을 해주는 쿼리가 같이 들어있었기 때문에 이 로직이 실행되기 이전에 flush를 수행하여 save가 제대로 반영되지 않고 DataIntegrityViolationException이 발생하게 된 것이다.
이를 예방하기 위해서는 너무 DB레이어의 UK 제약조건만 믿고 try-catch만을 심어서 데이터를 체크해주는 그런 부분을 지양해야 된다고 생각이 들었다.
1. 반드시 중복 데이터가 들어가지 못하게 만드는 기능이라면, 이전에 이미 등록된 데이터가 있는지 여부를 확인하는 로직을 넣어주는 것도 좋은 구성인 것 같다.
2. 만약에 db uk 예외가 발생하는 경우라면 @Transactional 을 적재적소에 알맞는 위치에 넣어 구성해주고, 그 @Transactional 을 사용하는 부분에 정말로 try-catch가 필요한지 다시한번 생각해볼 필요가 있다. (무지성 트랜잭셔널 금지!!)
다시는 재발하지 않게 로직을 구성해주자~