Real Mysql
real mysql 책을 읽으면서 스터디 한 내용을 정리하고자 한다.
일단 11.1 부터 11.3까지의 내용만을 정리했다.
내가 사용하는 애플리케이션에서 특정 데이터를 테이터베이스에 저장하거나 조회를 할 때
SQL이라는 문장을 사용해야 한다.
데이터베이스의 테이블이나 구조를 변경할때는 DDL(데이터 정의 언어)
테이블의 데이터를 조작을 위한 언어는 DML(데이터 조작 언어) 이다.
SQL작성 규칙은 mysql의 서버 시스템 정책에 따라 바뀔 수 있다.
이 정책은 데이터베이스에 어떤 테이블의 데이터들이 들어가지 않았을 때 설정하는 것이 중요하다.
영문 대소문자 구분
Mysql에서는 설치된 운영체제에 따라서 대소문자를 구분하는데,
DB의 테이블이 디스크의 디렉토리나 파일로 매핑이 되기 때문이다.
윈도우의 명령 프롬프트에서는 대충 디렉토리를 대소문자 구분하지 않고
Tap키를 눌러 자동완성을 시키면 그냥 그 알파벳에 맞는 디렉토리를 자동완성 시킨다.
반면에 유닉스 계열에서는 대소문자를 구분해서 대문자로 시작하는 디렉토리를 소문자부터 눌러서 Tap키를 누르면 찾지를 못한다.
그래서 운영체제를 옮기면서 db를 이관할 경우 문제가 생길 수 있기 때문에
Mysql 설정 파일에 lower_case_table_name 시스템 변수를 설정해주면 된다.
Mysql 예약어
데이터베이스 테이블에 예약어와 겹치는 키워드로 생성하는 경우
역따옴표나 큰따옴표로 감싸주어야 한다.
근데 이 감싸주는 행동 때문에 애를 먹을 수 있다.
단순 조회에서도 에러가 나올텐데 이 에러가 상세 정보를 나타내주는 것이 아니라 문법 오류라고만 띄워준다고 한다.
테이블을 생성해주어야 할 때에도 역따옴표를 넣지않고 생성을 해보다가 에러를 맞는 방법이 좋을것 같다.
그리고 무엇보다 최선의 방법은 예약어 키워드와 같은 테이블을 만들지 않는것이
가장 좋은 방법이다.
문자열
나는 이 문자열이 좀 신기했는데,
자동으로 다른 칼럼으로 형변환해서 비교한다는게 조금 신기했었다.
SELECT * FROM Member
WHERE number = '123';위와 같이 정수형인 컬럼에 문자열로 데이터를 조회하면
조건에 해당하는 저 문자열만 숫자로 자동 형변환이 들어가게 되니까 성능상 문제는 존재하지 않는다.
하지만 역으로 문자열 컬럼이지만 숫자데이터만 저장되어있는 경우에
SELECT * FROM Member
WHERE zipcode = 10001;우편번호를 형식만 숫자인 문자열로 저장했다고 했을 때 숫자형으로 조건을 검색하면
zipcode에 해당하는 값을 전부 형변환하면서 하나씩 탐색하기 때문에
형변환에 대한 리소스를 많이 잡아먹는다. 이렇게 비교하는건 좋지 않다.
그리고 zipcode가 보편적으로 숫자가 99% 이겠지만, 만약 문자가 들어간게 하나라도 있었다면 위의 조건은 에러를 뱉게 될 것이다.
DATE
이부분은 따로 뗴어져서 있었지만, 마찬가지로 위에서 봤던것 처럼
이 날짜부분도 자동으로 형변환이 된다.
그래서 문자를 Date형식으로 치환하는 어떤 함수를 쓰지 않아도 된다.
그리고 문자열로 조회한다고 해서 인덱스를 못타는 것도 아니다.
Boolean
나는 이부분을 보자마자 바로 tinyint(1) 을 떠올렸다.
true는 1, false는 0으로 나타내주지만,
이것을 정수형 변수에 넣어도 동작한다.
대신 false는 딱 0만 표현이 되는데,
true라고 해서 1 이상의 값들을 표현해주지는 못한다.
그래서 사용할거라면 tinyint(1)로 제한해서 쓰는게 좋을것 같다고 봤다.
더 많은 상태가 필요하다면 Enum을 사용하는게 바람직하다고 생각한다.
Like 연산자
이 연산자를 통해서 정규표현식을 사용하는 연산자보다는 좀 넓은 범위로 검색할 수 있는데 대신 인덱스를 사용할 수가 있다.
- Like에서 사용하는 와일드카드
%: 0 또는 1개 이상의 모든 문자에 일치하는지_: 정확히 1개의 문자 일치
이 와일드카드들을 직접 문자열에 넣어서 탐색하고 싶다면
ESCAPE를 추가해서 검색하면 된다.
~로 시작하는 칼럼을 찾는 데에는 인덱스 레인지 스캔을 적용해서 탐색하는게 빠르지만,
~로 끝나는 칼럼을 찾는곳에서는 인덱스의 left-most 특성으로 인덱스 풀스캔을 진행하게 된다.
mysql의 B-Tree 인덱스를 이용한 검색은 100% 일치 또는 값의 앞부분(Left-most)만 일치하는 경우에 사용할 수 있다.
Between 연산자
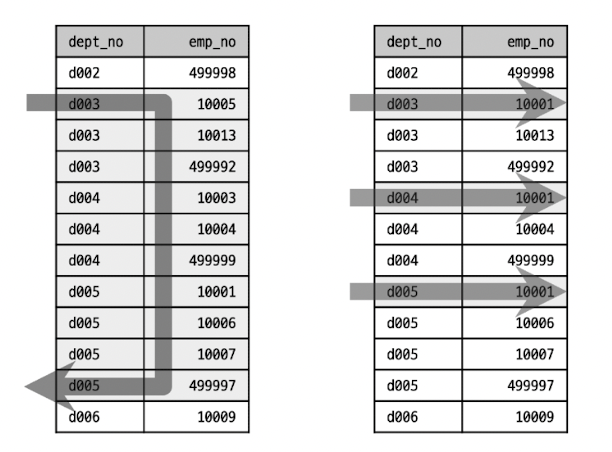
위의 이미지는 real mysql에서 가져온 이미지이다.
왼쪽이 Between 연산, 오른쪽이 In 연산이다.
특정 조건이 명확하게 보이는경우엔 In 연산자를 적용해주는 것이 훨씬 빠를것이다.
둘다 같은 데이터를 조회할 수는 있지만 범위를 지정하기 때문에 인덱스를 타지 않고 해당 조건을 쭉 조회하게 될 것이다.
다시 설명하면, 값이 불분명한 범위내에서 검색을 해야하면 Between을 사용해야 하지만, 명확한 경우라면 In절을 사용하는것이 훨씬좋다는것
Mysql 내장함수
여기서 다른 JSON에 대한 특정 문법들에 대한 내용도 나오지만,
쓸일이 많이 없을것 같아서 읽기만 했고 제대로 봤던건
NOW, SYSDATE의 차이
이 두개는 나는 자바를 엮어서 생각했다.
아마 그 부분이 맞을거라고 생각한다.
SELECT NOW(), SLEEP(2), NOW();
SELECT SYSDATE(), SLEEP(2), SYSDATE();NOW는 한 명령에 대해 동일한 시간을 가지고 2초를 지나서 데이터를 출력해주니까 값이 같다.
반면, SYSDATE는 한 명령이 아니라 그 자체의 함수가 있을때마다 즉각적으로 실행을 하기 때문에 두 값에 차이가 있다.
이게 이해가 잘 안된다면 아래의 자바 코드로 생각해보면 될 것 같다.
public class Demo {
public static void main(String[] args) {
LocalDateTime now = LocalDateTime.now();
System.out.println(now);
Thread.sleep(2000);
System.out.println(now);
System.out.println(LocalDateTime.now());
Thread.sleep(2000);
System.out.println(LocalDateTime.now());
}
}이 두개 방식의 차이이다.
그래서 조건식에 현재 시간을 여러번 넣어야하는 경우라면 NOW()를 쓰고
자바에서는 위쪽에 한번 선언한것으로 전부 넣어서 조회를 해주어야 조건이 제대로 동작할 것이다.
정리
11.3장이 MYSQL의 내장함수 설명부분이라 특정 함수들이 많아서
읽는데에 조금 분량이 많았던 것 같다.
다 같이 같은 공간에서 한번에 읽고 토론하는 시간을 가지니까
몰랐던부분도 이해하게 되고 집단지성으로 이게 이런의미구나! 라는걸 가져갈 수 있는 장점이 있다고 생각한다.
개발자에게 있어서 이 책은 2장이 더 괜찮을거라는 추천들 때문에 2장부터 보지만, 더 나아가서는 1장도 봐야 이해가 더 쉬울거라고 본다.